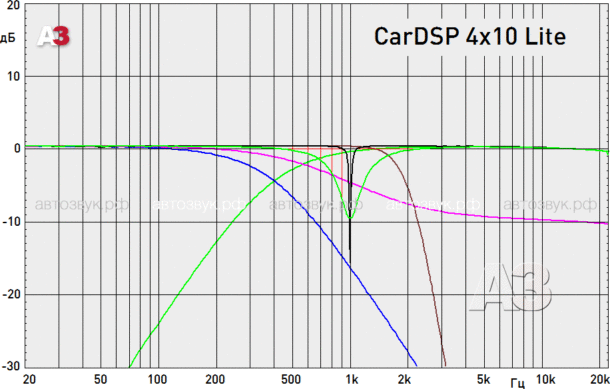
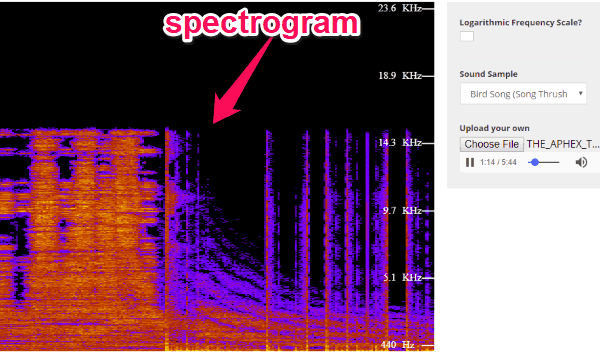
Spectrum lab — новый спектроанализатор на основе звуковой карты пк
Содержание:
- Поколение
- Academo Spectrum Analyzer:
- Sonification
- Мел-спектрограммы
- Cпектрограмма
- Renderer
- Электросаксофон: проект создания EWI шаг за шагом
- Новости музыкального софта
- Формирование
- Звук и свет против улицы: поражающие факторы, последствия для здоровья, возможные средства защиты и первая помощь
- Pre-calculated curves
- При чем же здесь SincNet?
- Audio Spectrogram Creator:
- PAS Analysis Center v3.5
- Представление
- Новости музыкального оборудования
- Lissajous Figures
- Обработка аудиоданных с помощью Python
- Ограничения и пересинтез
- Пополнения софта для Windows
- Классификация жанров музыки с помощью ANN
- Формат
- Выводы
Поколение
Спектрограммы обычно создаются одним из двух способов: приближенный как filterbank, который следует из серии полосовых фильтров (это было единственным путем перед появлением современной обработки цифрового сигнала), или вычислил от сигнала времени, используя FFT. Эти два метода фактически формируют две различных Плотности распределения времени, но эквивалентны при некоторых условиях.
Метод полосовых фильтров обычно использует обработку аналога, чтобы разделить входной сигнал на диапазоны частот; величина продукции каждого фильтра управляет преобразователем, который делает запись спектрограммы как изображения на бумаге.
Создание спектрограммы, используя FFT является цифровым процессом. В цифровой форме выбранные данные, во временном интервале, разбиты в куски, которые обычно накладываются, и Фурье, преобразованный, чтобы вычислить величину спектра частоты для каждого куска. Каждый кусок тогда соответствует вертикальной линии по изображению; измерение величины против частоты в течение определенного момента вовремя. Спектры или заговоры времени тогда «положены рядом», чтобы сформировать изображение или трехмерную поверхность, или немного перекрыты различными способами, windowing.
Спектрограмма сигнала s (t) может быть оценена, вычислив брусковую величину STFT сигнала s (t), следующим образом:
Academo Spectrum Analyzer:
Academo Spectrum Analyzer is one of the best free online audio spectrogram generator. You can use it to easily generate a spectrogram graph of any audio. It lets you use some sample sounds to see the spectrogram or you can upload your own audio file. After uploading an audio file, you can play it using the built-in player and it will start generating the spectrogram moving from right to left. You will see the color-coded spectrogram in real-time on the frequency by time graph as the audio is being played. It also comes with an option that lets you toggle logarithmic and linear frequency scale as per your requirement.
Sonification
Sonifying parametric equations is a matter of creating two channels of audio, one for the \(x\) variable and one for the \(y\). Equations 1 and 2 can be sonified using two Web Audio oscillator nodes, as long as the phase difference between the two oscillators is \(\pi/2\). At the time of writing, phase control of oscillator nodes is unavailable in Web Audio but is in development. However, we can still create a phase offset by using a with its set to one quarter of a period of the current frequency.
For more complicated parametric equations, an alternative approach is to create a stereo and fill the left and right buffers with data that has been calculated programatically using the parametric equation for that channel. This is done over a certain range of \(t\) (ideally one which contains a whole number of periods which therefore avoids discontinuities and audio artefacts) and the property of the buffer is set to .
Мел-спектрограммы
Чтобы понять суть этой статьи, давайте сначала вспомним, что такое мел-спектрограмма, как ее получить и в чем ее смысл. Если эта тема вам знакома, то эта часть будет не очень интересной. Ее вычисляют по обычной спектрограмме, построенной с помощью оконного преобразования Фурье:
Суть этой операции в последовательном применении преобразования Фурье к коротким кусочкам речевого сигнала, домноженным на некоторую оконную функцию. Результат применения оконного преобразования — это матрица, где каждый столбец является спектром короткого участка исходного сигнала. Посмотрите на пример ниже:
Эксперименты ученых показали, что человеческое ухо более чувствительно к изменениям звука на низких частотах, чем на высоких. То есть, если частота звука изменится со 100 Гц на 120 Гц, человек с очень высокой вероятностью заметит это изменение. А вот если частота изменится с 10000 Гц на 10020 Гц, это изменение мы вряд ли сможем уловить.
В связи с этим была введена новая единица измерения высоты звука — мел. Она основана на психо-физиологическом восприятии звука человеком, и логарифмически зависит от частоты:
Собственно, мел-спектрограмма — это обычная спектрограмма, где частота выражена не в Гц, а в мелах. Переход к мелам осуществляется с помощью применения мел-фильтров к исходной спектрограмме. Мел-фильтры представляют из себя треугольные функции, равномерно распределенные на мел-шкале. В качестве примера здесь изображены 10 мел-фильтров (на практике их берут больше, здесь их мало для наглядности):
При переводе в частотную шкалы, те же самые фильтры будут выглядеть так:
Каждый столбец исходной спектрограммы скалярно умножается на каждый мел-фильтр (размещенный на частотной шкале), после чего получается вектор чисел, по размеру равный количеству фильтров. На картинке ниже изображен один из столбцов спектрограммы (значения амплитуды переведены в логарифмический масштаб для наглядности, то, что на картинке кодировалось цветом, здесь отражено по оси ординат) и два мел-фильтра, с помощью которых строится мел-спектрограмма:
В результате таких преобразований значения из низких частот спектрограммы остаются практически неизменными на мел-спектре, а в высоких частотах происходит усреднение значений из более широкого диапазона. В качестве примера предлагаю посмотреть на мел-спектрограмму, построенную по предыдущей спектрограмме с использованием 64 мел-фильтров:
Резюмируя все вышесказанное: на мел-спектрограмме сохраняется больше информации, которая хорошо воспринимается и различается человеком, чем на обычной спектрограмме. Иными словами, такое представление звука больше сфокусировано на низких частотах, и меньше — на высоких.
Cпектрограмма
Спектрограмма — это визуальный способ представления уровня или «громкости» сигнала во времени на различных частотах, присутствующих в форме волны. Обычно изображается в виде тепловой карты.
Отобразить спектрограмму можно с помощью .
преобразует данные в кратковременное преобразование Фурье. С помощью STFT можно определить амплитуду различных частот, воспроизводимых в данный момент времени аудиосигнала. Для отображения спектрограммы используется .

На вертикальной оси показаны частоты (от 0 до 10 кГц), а на горизонтальной — время. Поскольку все действие происходит в нижней части спектра, мы можем преобразовать ось частот в логарифмическую.
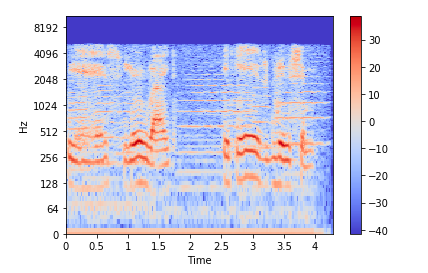
Создание аудиосигнала:
Renderer
13
| Голос | Speed | Pitch | Throat | Mouth | |
|---|---|---|---|---|---|
| Elf | 72 | 64 | 110 | 160 | |
| Little Robot | 92 | 60 | 190 | 190 | |
| Stuffy Guy | 82 | 72 | 110 | 105 | |
| Little Old Lady | 82 | 32 | 145 | 145 | |
| Extra-Terrestrial | 100 | 64 | 150 | 200 | |
| SAM | 72 | 64 | 128 | 128 | |
| DALEK | 120 | 100 | 100 | 200 |
прошлогодней статье
- : для гласных и сонорных фонов (коды 5–29 и 48–53) табличные значения частот F1 и F2 домножаются на параметры Mouth и Throat соответственно.
- : для каждого фона записывается соответствующее его длительности число значений в восемь названных параллельных списков. Сами значения берутся из таблиц по коду фона, при этом тоны переводятся из условной шкалы (1–8) в величину прибавки к параметру Pitch (1 → −32, 6 → 0, 8 → +12). Кроме того, точки и вопросительные знаки превращаются в плавное (на протяжении 30 фреймов) понижение или повышение тона, соответственно.
- : значения частот F–F3 и амплитуд F1–F3 на границе между соседними фонами линейно интерполируются. Ширина границы, внутри которой выполняется интерполяция, зависит от кодов обоих фонов.
- Частота F заменяется средним значением между ней и F1, чтобы создать «pitch contour», с которым синтезированная речь будет звучать не так монотонно.
- Наконец, значения амплитуд после интерполяции переводятся из логарифмической шкалы (децибелы) в линейную, используемую в стандартном PCM.
Электросаксофон: проект создания EWI шаг за шагом
Вступление, или откуда что берется
Карьера программиста и инженера вообще — очень интересная штука, и зачастую приводит к управлению проектами, как и случилось у меня в T-Systems. Руководство проектами – это прекрасно: и опыт, и почет, и уважение, но простора для инженерной деятельности там не остается. А руки-то помнят! (с)
Остается использовать полученные знания и навыки в своих сторонних проектах, благо, такая возможность есть.
О чем я сегодня расскажу
Кроме всего прочего, я еще немного (лет 5-6) саксофонист. И все хорошо в этом прекрасном инструменте, но уж очень он громкий. И с первых своих уроков я мечтал о появлении в моей жизни такого же саксофона, но чтобы можно было играть на нем в наушниках и не донимать соседей, чтобы был этакий тренировочный инструмент.
Конечно, существуют электронные духовые инструменты, флагманы — AKAI EWI и Roland Aerophone, но, во-первых, они очень компромиссные с точки зрения положения пальцев и вообще эргономики (не говоря уже про амбушюр), а во-вторых, кроме них, ничего на рынке и нет, а эти стоят 60+к. Извините, но мой сакс — американец CONN — стоит в 2 раза дешевле (весьма подержанный, впрочем, но еще меня переживет). Так что задушили они меня вдвоем — жаба и жажда деятельности. Будем делать электросакс.
Новости музыкального софта
-
04 февраля, 2019
Synth One от компании AudioKit получил высокую оценку для iPad-версии не только из-за превосходного звучания. Этот бесплатный гибридный аналоговый/FM…
-
Digital Performer 10 от MOTU идут по пути Ableton
04 февраля, 2019Digital Performer от MOTU всегда была одной из «традиционных» рабочих станций, которая работает в классическом стиле линейной аранжировки….
-
Instant Phaser Mk II от Eventide — сверхточный эмулятор железа
27 января, 2019Instant Phaser компании Eventide открыл новое направление в далёком 1972 году. Eventide утверждают, что это был первый в истории электронный…
-
Анонсирован Korg Gadget 2
23 января, 2019Рабочая станция Gadget от Korg хорошо зарекомендовала себя на iOS и вторая версия — это не только улучшение мобильного приложения, но и новая…
-
120 бесплатных ультрасовременных басовых сэмплов
14 января, 2019Коллекция SampleRadar начиналась с многооктавных осцилляторов с небольшой тональной расстройкой. Затем их использовали для записи басовых линий,…
Формирование
Спектрограмма обычно создаётся одним из двух способов: аппроксимируется, как набор фильтров, полученных из серии полосовых фильтров (это был единственный способ до появления современных методов цифровой обработки сигналов), или рассчитывается по сигналу времени, используя оконное преобразование Фурье. Эти два способа фактически образуют разные квадратичные частотно-временные распределения, но эквивалентны при некоторых условиях.
Метод полосовых фильтров обычно используется в аналоговой обработке для разделения входного сигнала на частотные диапазоны.
Создание спектрограммы с помощью оконного преобразования Фурье обычно выполняется методами цифровой обработки. Производится цифровая выборка данных во временной области. Сигнал разбивается на части, которые, как правило, перекрываются, и затем производится преобразование Фурье, чтобы рассчитать величину частотного спектра для каждой части. Каждая часть соответствует вертикальной линии на изображении — значение амплитуды в зависимости от частоты в каждый момент времени. Спектры или временные графики располагаются рядом на изображении или трёхмерной диаграмме.
Спектрограмма сигнала s(t) может быть оценена путём вычисления квадрата амплитуды оконного преобразования Фурье сигнала s(t), следующим образом:
- spectrogram(t,ω)=|STFT(t,ω)|2{\displaystyle \mathrm {spectrogram} (t,\omega )=\left|\mathrm {STFT} (t,\omega )\right|^{2}}
Звук и свет против улицы: поражающие факторы, последствия для здоровья, возможные средства защиты и первая помощь
Сегодня сложно не замечать уличную протестную активность, которая проявляется во всём мире по разнообразным поводам. По сей день продолжаются массовые протесты в городах Республики Беларусь, начавшиеся 9 августа после президентских выборов. Несмотря на преимущественно мирный характер акций, там впервые за историю страны против протестующих использовали световое и звуковое оружие. Ранее, по сообщениям местных СМИ, использовали только щиты и демократизаторы (тоталитаризаторы, резиновые палки).
Звуковое и световое оружие используется сравнительно давно и появилось как контртеррористические нелетальные спецсредства. Позже его достоинства оценили подразделения, применяющиеся для протестующих на улицах. Те, кто не испытывал поражающее действие таких устройств на себе, обычно считают, что они “не очень опасны” и “достаточно гуманны”. В этом посте я постараюсь рассказать всё о “гуманности” звукового и светового оружия, которое применяется для подавления протестов, а также опишу последствия его использования и средства защиты от него. Я постараюсь сделать акцент на спецсредствах, которые уже используются на минских улицах, а также на тех, которые, по информации некоторых телеграм-каналов, планируют использовать против протестующих.
Pre-calculated curves
Producing more complex plots can be done by adding large numbers of sinusoids together. While it should be possible to recreate these by creating large numbers of corresponding oscillator nodes, the author has for the following cases decided to create an empty buffer and programatically calculate the required samples over a single period.
To introduce time evolution, this process can be repeated over a number of periods. For each period, a transformation is applied to the samples. The transformation is then adjusted slightly for the next iteration. In this way, the author was able to create a spinning ballerina, and a jumping dolphin.
Please enable JavaScript to view the comments powered by Disqus.
При чем же здесь SincNet?
Вспомним, что мел-шкала была создана на основе человеческого психо-физического восприятия звука. Но что если мы хотим выбрать другие полосы частот, которые нас интересуют больше чем остальные в какой-либо конкретной задаче? Как выбрать самый лучший набор фильтров для решения какой-либо задачи?
Именно эту задачу и решает предложенная авторами архитектура.
Авторы рассматривают в качестве фильтра следующую функцию:
в этой формуле — это прямоугольная функция. Такой фильтр задает диапазон частот от до . Вот ее график:
С помощью обратного преобразования Фурье для этой функции можно получить ее аналог во временной области:
Функция — это импульсная характеристика идеального полосового фильтра, который нельзя реализовать практически, поэтому авторы усекают эту функцию . В цифровой обработке сигналов такой подход называется синтезом фильтров методом окон.
Усеченный окном вариант функции авторы предлагают использовать в качестве шаблона для всех сверток, применяемых к сырым аудио данным. Эта функция дифференцируема по параметрам и , а значит ее можно использовать при оптимизации параметров сети методом обратного распространения ошибки.
По теореме о свертке, свертка исходного сигнала с функцией эквивалентна умножению спектра исходного сигнала на функцию
Грубо говоря, выполняя свертку исходного сигнала с функцией , мы «обращаем внимание» нейронной сети на данный диапазон частот в рассматриваемом сигнале
Конечно, здесь не применяется преобразование Фурье и явно нейросети не сообщаются конкретные значения спектра в диапазоне . По всей видимости, задача извлечения спектральных характеристик возлагается на следующие блоки, расположенные в нейронной сети.
Из достоинств такого подхода, авторы отмечают следующее:
- Быстрая сходимость
- Гораздо меньшее количество параметров. В классическом сверточном блоке количество параметров равно длине свертки. При описанном же подходе, количество параметров не зависит от длины свертки и равно 2
- Интерпретируемость параметров
Audio Spectrogram Creator:
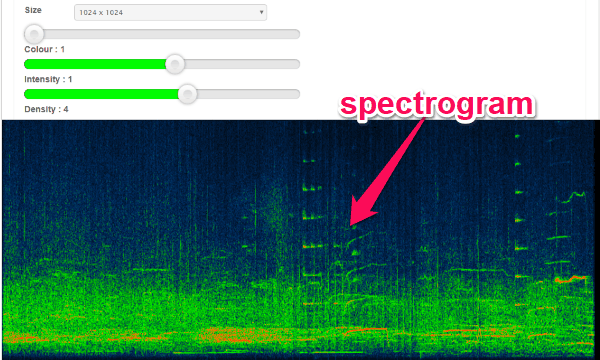
Audio Spectrogram Creator is also a pretty useful online audio spectrogram creator that can take an audio file as input and gives a spectrogram graph as output. You can simply open up this spectrogram generator and then upload any audio file you want from PC. It supports MP3, M4A, and WMV files. After that, it allows you change the look of the spectrogram graph by changing its size, color, intensity, and density. Once you’re done, click the “Ok” button to proceed. Unlike the spectrogram generator explained above, this one doesn’t actually generate the spectrogram in real-time, but instead, generates an image of the spectrogram graph.
PAS Analysis Center v3.5
Итак, начнем по порядку: запустив программу мы видим несколько окон (рис. 1). Вот их мы и будем рассматривать далее.
Рисунок 1. Окна в PAS Analysis Center v3.5
Первое из окон — Spectrum Analyzer, собственно анализатор спектра. На первой вкладке (FFT Length) производятся настройки для преобразования Фурье (собственно, сам процесс представления сигнала в спектральном виде). Blackman, Hamming, Parzen и пр. — это так называемые «окна», проще говоря это имена математиков, которые предложили каждый свою весовую функцию для представления спектра звука. Если хотите ощутить между ними разницу, то включите генератор (рис. 2) и сгенерируйте синусоиду (Sine).
Рисунок 2. Включаем генератор
Так как синусоида должна в идеале давать один пик в спектральной области, то можно переключать вышеупомянутые «окна» и посмотреть на результат.
Следующий параметр — FFT Length. Это количество отсчетов при Фурье-преобразовании. Чем это значение больше, тем точнее спектральная характеристика но медленней процесс. И наоборот.
Следующая вкладка — Scale. Здесь находятся настройки шкалы спектроанализатора. Все три характеристики регулируют растяжение/сжатие по осям.
Display. В этой вкладке находятся настройки вида спектроанализатора.
Log Amplitude и Log Frequency — логарифмическая либо линейная шкалы по соответствующим осям. Draw grid — прорисовка сетки. Draw inactive — подсветка спектральных полос. Draw amplitude scale и Draw frequency scale — отображать градуировку шкалы уровня и частоты соответственно. Draw peaks — прорисовка пиковых значений. Peaks hold — отображение последнего пикового значения.
Kind — тип визуализации спектра. Тут особо интересный режим Scroll, т.к. в этом режиме еще включается 3-е измерение — время.
Peaks — настройка отображения пиков. Numbers — толщина пиков. Peak delay — задержка пиков. Peak speed — скорость спада пиков.
Decay — настройка времени регенерации спектральных столбцов. Необходимо для коррекции скорости, т.е. чтоб они не прыгали с бешенной скоростью или наоборот не ворочались еле-еле.
Рисунок 3. Осциллограф
Следующее окно Oscilloscope (осциллограф) (рис. 3). Он показывает форму волны в случае звука, а в общем случае изменение напряжения (или тока в зависимости от подключения) анализируемого сигнала.
FFT Length — как я уже говорил, это настройка для преобразования Фурье.
Scale — здесь настройка подписей шкал. Effect — выбирается разделение по цвету для пиков (Peaks) или для верхней/нижней части (Splitt).
Display — настройка вида. Здесь стоит выделить Scroll — значительное сжатие по времени, удобно для наблюдения более общей картины.
Outfits — тип прорисовки волны.
Trigger mode — эта функция похожа на функцию синхронизации в осциллографах. И полезна она для анализа музыки вряд-ли будет. Up Flag и Down Flag — по какому фронту синхронизировать (заметно на пилообразных сигналах). Trigger level — уровень срабатывания.
И последнее окно — Spectrogram (рис. 4) это фактически перевернутый спектр, растянутый по времени. Амплитуда (уровень) здесь отображается цветом.
Рисунок 4. Спектрограф
FFT Length — см. ранее.
Scale — установки шкалы и усиления. Amp scale — усиление. Sensitive — чувствительность. Freq scale — степень растяжения оси частоты. Freq base — основная (нижняя) частота.
Display — настройки отображения спектрограммы. Accelerate — ускорение во времени. Embossed — смена фона спектрографа, особо эффектно бывает при других подстройках (Black-White в Outfit). Scroll display — прокручивать дисплей по прохождении или возвращаться назад.
Outfit — цветовые настройки спектрограммы.
На этом обзор окон закончен.
Теперь я хочу немного сказать об основных принципах работы этой программы, да и других подобных ей (анализаторов сигнала).
Существует 3 режима работы таких программ: 1. Вживую (анализ звука в реальном времени со входа звуковой платы). Здесь смотри рисунок 5
Рисунок 5. «Живой» режим
2. Проигрыватель файлов. Анализирует уже записанные файлы (см. рис. 6)
Рисунок 6. Режим плеера
3. Режим генератора. О нем я уже упоминал выше (см. рис.2). Полезен для подстроек и настроек.
Представление
Часть музыкального произведения в трёхмерном представлении
Наиболее распространенным представлением спектрограммы является двумерная диаграмма: на горизонтальной оси представлено время, по вертикальной оси — частота; третье измерение с указанием амплитуды на определенной частоте в конкретный момент времени представлено интенсивностью или цветом каждой точки изображения.
Есть много вариантов представления: иногда вертикальная и горизонтальная оси включены так, что время бежит вверх и вниз, иногда амплитуда представлена вершинами в трёхмерном пространстве, а не цветом или интенсивностью. Частота и амплитуда осей может быть линейными или логарифмическими, в зависимости от того, с какой целью используется график. Аудио обычно может быть представлено с логарифмической осью амплитуды (зачастую, в децибелах или дБ), и частота будет линейной, чтобы подчеркнуть гармонические отношения, или логарифмической, чтобы подчеркнуть музыкальные, тональные отношения.
Новости музыкального оборудования
-
2 новинки от Rane DJ: микшер SEVENTY-TWO MKII и контроллер TWELVE MKII
06 августа, 2020RANE SEVENTY-TWO MKII — это двухканальный микшер с расширенными возможностями управления, который раскрывает всю творческую мощь программного…
-
Российский завод «Октава» и британский музыкальный ритейлер Andertons будут сотрудничать
19 июня, 2020Российский завод «Октава» заключил контракт на дистрибуцию микрофонов на территории Соединенного Королевства Великобритании и Северной…
-
TC Electronic анонсировали PolyTune 3 Mini и Noir
17 апреля, 2019TC Electronic уже давно находится списке лучших гитарных тюнеров в мире, но не собирается останавливаться на достигнутом. Фирма анонсировала…
-
Line 6 выпускают беспроводную гитарную педаль Relay G10S
04 февраля, 2019Line 6 представили беспроводную систему Relay G10S, предназначенную для интеграции с педальными панелями в виде прочной металлической педали,…
-
Arturia расширяют линейку аудиоинтерфейсов AudioFuse
30 января, 2019Интерфейс AudioFuse выглядел немного одиноким в линейке продуктов Arturia, поэтому компания решила пополнить линейку аудиоинтерфейсов. В результате…
Lissajous Figures
In their most general form, Lissajous Figures are created from the following pair of parametric equations:
For simplicity, our demo has \(A = B = 1\). Two oscillator nodes are created, with adjustable frequencies determined by \(a\) and \(b\). The relative phase offset between them would be \(\delta\). Due to the lack of precise phase control as mentioned earlier, the \(\delta\) slider in the demo doesn’t represent an accurate phase offset (as the oscillator’s relative phase changes when the frequency changes) but nevertheless still provides a way to nudge the phase and adjust the visualization.
Lissajous patterns can range from very simple to very intricate depending on the ratio of \(a:b\). In terms of sound, they are very simple — two pure tones.
Обработка аудиоданных с помощью Python
Звук представлен в форме аудиосигнала с такими параметрами, как частота, полоса пропускания, децибел и т.д. Типичный аудиосигнал можно выразить в качестве функции амплитуды и времени.
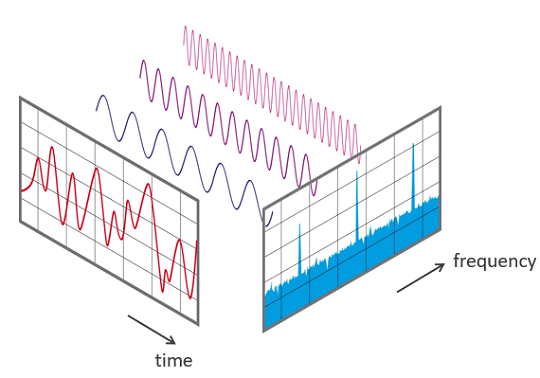
Время/частота.
Некоторые устройства могут улавливать эти звуки и представлять их в машиночитаемом формате. Примеры этих форматов:
- wav (Waveform Audio File)
- mp3 (MPEG-1 Audio Layer 3)
- WMA (Windows Media Audio)
Процесс обработки звука включает извлечение акустических характеристик, относящихся к поставленной задаче, за которыми следуют схемы принятия решений, которые включают обнаружение, классификацию и объединение знаний. К счастью, некоторые библиотеки Python помогают облегчить эту задачу.
Аудио библиотеки Python
Мы будем использовать две библиотеки для сбора и воспроизведения аудио:
1. Librosa
Это модуль Python для анализа звуковых сигналов, предназначенный для работы с музыкой. Он включает все необходимое для создания системы MIR (поиск музыкальной информации) и подробно задокументирован вместе со множеством примеров и руководств.
Установка:
Для повышения мощности декодирования звука можно установить ffmpeg, содержащий множество аудио декодеров.
2. IPython.display.Audio
С помощью можно проигрывать аудио прямо в jupyter notebook.
Сюда загружен случайный аудиофайл. Попробуем передать его в консоль jupyter.
Загрузка аудиофайла:
Этот фрагмент возвращает звуковой временной ряд в качестве массива numpy с частотой дискретизации по умолчанию 22 кГц моно. Это поведение можно изменить с помощью повторного семплинга на частоте 44,1 кГц.
Повторный семплинг также можно отключить:
Частота дискретизации — это количество аудио семплов, передаваемых в секунду, которое измеряется в Гц или кГц.
Проигрывание аудио:
С помощью можно проигрывать аудио в jupyter notebook.
Этот фрагмент возвращает аудиовиджет:

Визуализация аудио:
С помощью можно построить график массива аудио:

Ниже представлен график управления амплитудой формы волны:
Ограничения и пересинтез
От формулы выше, кажется, что спектрограмма не содержит информации о точном, или даже приблизьтесь, фаза сигнала, что это представляет. Поэтому не возможно полностью изменить процесс и произвести копию оригинального сигнала от спектрограммы, хотя в ситуациях, где точная начальная фаза неважна, может быть возможно произвести полезное приближение оригинального сигнала. Спектрограф Звука Анализа & Пересинтеза http://arss .sourceforge.net является примером компьютерной программы, которая пытается сделать это. Воспроизведение Образца было ранним речевым синтезатором, разработанным в Лабораториях Haskins в конце 1940-х, которые преобразовали картины акустических образцов речи (спектрограммы) назад в звук.
Фактически, в спектрограмме есть некоторая информация о фазе, но это появляется в другой форме как временная задержка (или задержка группы), который является двойной из Мгновенной Частоты.
Размер и форма аналитического окна могут быть различны. Меньшее (более короткое) окно приведет к более точным результатам в выборе времени, за счет точности представления частоты. Большее (более длинное) окно обеспечит более точное представление частоты, за счет точности в выборе времени представления.
Пополнения софта для Windows
-
Surge v1.7.030 июля 2020
Surge — это субтрактивный VST синтезатор. Цифровая запись — всего лишь последовательность чисел в нулях и еденицах, сохраненная на физических носителях, объединенных вместе
-
Wavosaur v1.730 июля 2020
Wavosaur — бесплатный звуковой редактор. Имеет все основные возможности такого класса программ: монтаж, анализ, пакетная обработка. Wavosaur поддерживает VST-плагины, ASIO-драйверы,
-
Nils K1v05 июля 2020
VST-ромплер, имитирующий синтезатор Kawai KM1, известная японская классика 1988 года.K1v имеет 8-битный механизм синтеза с 4 источниками на голос и полноценную реализацию
-
Imaginando DLYM v2.027 июня 2020
DLYM — это бесплатный плагин, который производит эффекты в стиле фленджер и хоруса с использованием мощной технологии обработки Imaginando.Независимо от того, хотите ли вы
-
Moncasual Giada Loop Machine v0.16.3.124 июня 2020
Приложение, созданное как минималистский. Хардкорный аудио-инструмент для ди-джеев и тех, кто выступает вживую. Giada — это бесплатный аудио-инструмент для ди-джеев и тех,
Классификация жанров музыки с помощью ANN

Набор данных состоит из 1000 звуковых треков, длина каждого составляет 30 секунд. Он содержит 10 жанров, каждый из которых представлен 100 треками. Все дорожки — это монофонические 16-битные аудиофайлы 22050 Гц в формате .wav.
Жанры, представленные в наборе:
- Блюз
- Классика
- Кантри
- Диско
- Хип-хоп
- Джаз
- Метал
- Поп
- Регги
- Рок
Для работы с нейронными сетями мы будем использовать — бесплатный сервис, предоставляющий GPU и TPU в качестве сред выполнения.
План:
В первую очередь нужно преобразовать аудиофайлы в изображения формата PNG (спектрограммы). Затем из них нужно извлечь значимые характеристики: MFCC, спектральный центроид, скорость пересечения нуля, частоты цветности, спад спектра.
После извлечения признаки можно добавить в файл CSV, чтобы ANN можно было использовать для классификации.
Приступим!
- Извлекаем и загружаем данные в Google Drive, а затем подключаем диск в Colab.

Структура директорий Google Colab после загрузки данных.
2. Импортируем все необходимые библиотеки.
3. Теперь конвертируем файлы аудиоданных в PNG или извлекаем спектрограмму для каждого аудио.
Спектрограмма семпла песни в жанре блюз:
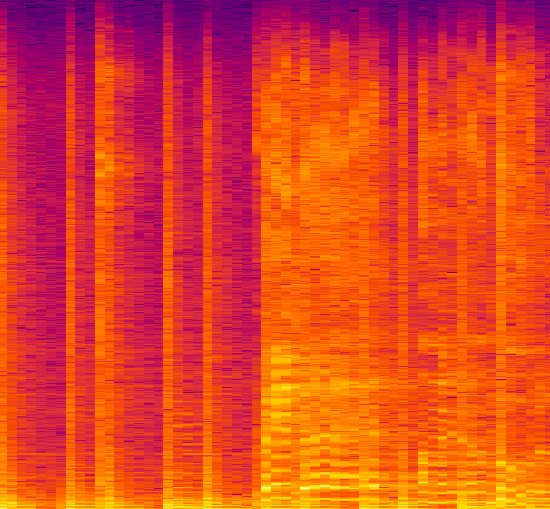
Преобразование аудиофайлов в соответствующие спектрограммы упрощает извлечение функций.
Создание заголовка для файла CSV.
5. Извлекаем признаки из спектрограммы: MFCC, спектральный центроид, частоту пересечения нуля, частоты цветности и спад спектра.
6. Выполняем предварительную обработку данных, которая включает загрузку данных CSV, создание меток, масштабирование признаков и разбивку данных на наборы для обучения и тестирования.
7. Создаем модель ANN.
8. Подгоняем модель:
После 100 эпох точность составляет 0,67.
Заключение
На этом первая часть подходит к концу. Мы провели анализ аудиоданных, извлекли важные признаки, а также реализовали ANN для классификации музыкальных жанров.
Во второй части попробуем выполнить то же самое с помощью сверточных нейронных сетей на спектрограмме.
- Максимальная производительность Pandas Python
- Продвинутые методы и техники списков в Python
- Автоматизация работы с Python
Перевод статьи Nagesh Singh Chauhan: Audio Data Analysis Using Deep Learning with Python (Part 1)
Формат
Стандартный формат — граф с двумя геометрическими аспектами: горизонтальная ось представляет время или rpm, вертикальная ось — частота; третье измерение, указывающее на амплитуду особой частоты в определенное время, представлено интенсивностью или цветом каждого пункта по изображению.
Есть много изменений формата: иногда вертикальные и горизонтальные топоры переключены, таким образом, время бежит вверх и вниз; иногда амплитуда представлена как высота 3D поверхности вместо цвета или интенсивности. Топоры частоты и амплитуды могут быть или линейными или логарифмическими, в зависимости от того, для чего используется граф. Аудио обычно представлялось бы с логарифмической осью амплитуды (вероятно, в децибелах или dB), и частота будет линейна, чтобы подчеркнуть гармонические отношения, или логарифмический, чтобы подчеркнуть музыкальные, тональные отношения.
Выводы
Фильтров, с помощью которых преобразуются спектрограммы, существуют много. Например, кроме описанных мел-фильтров, есть еще барк-фильтры (почитать можно здесь и здесь). По крайней мере барк — это тоже психофизическая величина, подобранная «под человека».
В своем исследовании авторы предложили метод, по которому можно заставить нейронную сеть самостоятельно выбрать наиболее подходящие диапазоны частот в процессе обучения в зависимости от набора данных. Как по мне, это очень похоже на процесс построения мел-спектрограммы, при котором больший приоритет отдается низким частотам
Вот только мел-спектрограммы придумали на основе человеческого восприятия звука, а в предложенном методе нейросеть сама решает, что важно, а что нет